A veces, dentro del proceso de indexación SEO, ocurren “pequeños líos” que, teniendo una solución muy sencilla, pueden ocasionarnos mucha incertidumbre…
Sabemos de sobra que la indexación es el proceso por el que Google y otros motores rastrean e incluyen webs en su índice para que puedan aparecer en los resultados de búsqueda… y si una página no está indexada, no recibirás tráfico desde ese buscador…
¿Pero… nos fijarnos en la cabecera HTTP y si hay algún parámetro no index en su meta???
¿Qué es el "noindex" y cómo afecta a la indexación?
El noindex es una directiva que le dice a los motores de búsqueda que no indexen una página en sus resultados… y se puede implementar de dos maneras principales:
A través de la etiqueta meta en el código HTML
<meta name=”robots” content=”noindex”>
A través de la cabecera HTTP
X-Robots-Tag: noindex
Su función es evitar que ciertas páginas, como las de contenido duplicado, privadas o sin relevancia para posicionar aparezcan en los resultados de búsqueda. Si una página tiene esta directiva, aunque los motores de búsqueda puedan rastrearla, no la incluirán en sus resultados.
Y esto es útil para mejorar la calidad del contenido indexado, para mostrar páginas relevantes pero sobretodo; para aprovechar el tiempo de rastreo…
Y es ahí donde pueden ocurrir “pequeños desastres”…
"Noindex" en las cabeceras HTTP
Un “noindex” puede afectar negativamente al SEO si se aplica de manera accidental en páginas clave tipo productos estrella o servicios importantes…
Al contrario de las metaetiquetas HTML, que se pueden ver en el código de la página y revisar fácilmente, las cabeceras HTTP son menos accesibles y pueden pasarnos totalmente desapercibidas durante un periodo hasta revisar las cifras de tráfico… y las pérdidas en posiciones.
Además, si una página con “noindex” en las cabeceras HTTP tiene enlaces internos valiosos, perderán relevancia y autoridad del dominio… incluso, si el “noindex” se combina con ciertos contextos de “nofollow” podrías aislar secciones enteras de sitios web clave en su indexación.
Y a todo eso, añade que Google y otros buscadores pueden tardar en procesar los cambios… es decir, que una página desindexada podría no recuperarse inmediatamente después de eliminar la directiva…
¿La clave…? Monitorear regularmente las cabeceras HTTP y revisar que sólo se apliquen a las páginas definidas…
¿Cómo saber si tu sitio está enviando "noindex" en las cabeceras HTTP?
Puedes confirmar especificaciones de “noindex” en cabeceras HTTP de varias maneras:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
Método 1: "Inspect Element" en Chrome
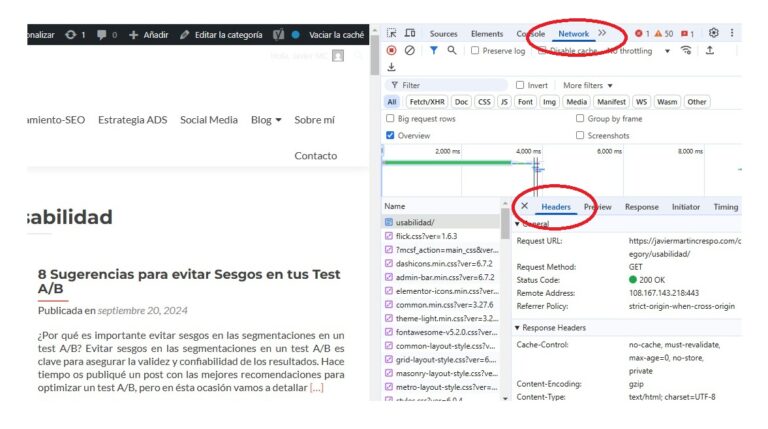
Dentro de Google Chrome y la página a revisar; presiona F12 o Ctrl + Shift + I para abrir las herramientas de desarrollador y ve a la pestaña Network…
Recarga la página (F5) y selecciona la primera solicitud que aparece en la lista. En la pestaña “Headers“ busca “X-Robots-Tag: noindex
Si aparece, significa que tu servidor está enviando la instrucción de no indexar.
Método 2: Curl (línea de comandos)
Un comando cURL es una herramienta de línea de comandos que se usa para transferir datos desde o hacia un servidor utilizando diferentes protocolos… y entre ellos HTTP, HTTPS, FTP… muy útil para depurar respuestas HTTP y analizar encabezados.
Si tienes acceso a una terminal, ejecuta el comando:
curl -I -L https://ejemplo.com
Si aparece “x-robots-tag: noindex” significa que la página está bloqueada para su indexación.
Si solo quisiéses filtrar el resultado y ver si existe la directiva noindex, usa:
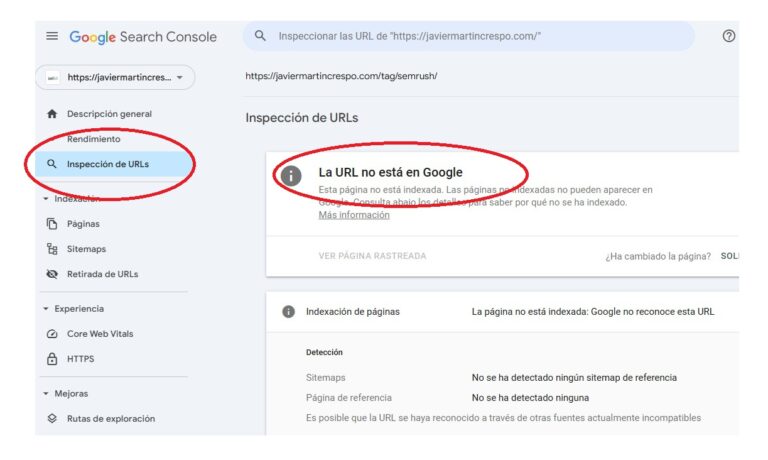
Entra a Google Search Console, ve a Inspección de URL e introduce la URL…
Si dice “La URL no está en Google”, confirma que Google está detectando la directiva.
¿Cómo solventar o anular el “Noindex”?
Antes de “solventar” el problema hay que tener claro donde está el “Noindex” e indagar por donde se está enviando al archivo…
Para encontrarlo:
Verifica el archivo .htaccess y localiza líneas como: “Header set X-Robots-Tag “noindex, nofollow”y cambia noindex a index
Echa un vistazo a la configuración de WordPress, Joomla o el CMS en cuestión…
Por regla general; dentro de Ajustes > habrá una opción para “Disuadir a los motores de búsqueda de indexar el sitio” y donde debes dejarla como NO marcado.
Tampoco está de más revisar plugins del tipo Yoast SEO o Rank Math por si la configuración puede estar añadiendo el noindex en las cabeceras.
Comprueba si hay reglas en el servidor web (Nginx, Apache…) y revisa la configuración en /etc/nginx/sites-available/tuweb.conf y buscando algo parecido a:
add_header X-Robots-Tag “noindex, nofollow”;
Y si existe… pues elimínalo o cámbialo a index.
Como reglas generales; éstas medidas localizarían y solventarían el nofollow… la última tarea a realizar sería confirmar que los cambios se han producido… es decir; volver a limpiar la cache en el CMS (WP Rocket, W3 Total Cache… ), volver a probar las cabeceras HTTP y volver a solicitar la reindexación en Google Search Console a ver si en un par de días la URL está indexada.
En conclusión…
El mayor riesgo de usar noindex en la cabecera HTTP es que los motores de búsqueda lo detectan antes de procesar el contenido sin llegar a indexarlo… es decir; aunque la página tenga información valiosa o enlaces importantes apuntando, simplemente desaparece del radar de Google.
Usar noindex en las cabeceras HTTP puede ser útil para evitar que ciertas páginas aparezcan en los resultados de búsqueda como contenidos temporales o privados… pero activarlo por error puede hundir la visibilidad y perder posicionamiento.
Para evitar sustos, lo mejor es revisar bien qué páginas llevan noindex y asegurarse de que se está usando solo cuando realmente hace falta.